Device 0: "GeForce 320M"
CUDA Driver Version / Runtime Version 5.5 / 5.5
CUDA Capability Major/Minor version number: 1.2
Total amount of global memory: 253 MBytes (265027584 bytes)
( 6) Multiprocessors x ( 8) CUDA Cores/MP: 48 CUDA Cores
GPU Clock rate: 950 MHz (0.95 GHz)
Memory Clock rate: 1064 Mhz
Memory Bus Width: 128-bit
Max Texture Dimension Size (x,y,z) 1D=(8192), 2D=(65536,32768), 3D=(2048,2048,2048)
Max Layered Texture Size (dim) x layers 1D=(8192) x 512, 2D=(8192,8192) x 512
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes
Total number of registers available per block: 16384
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 512
Maximum sizes of each dimension of a block: 512 x 512 x 64
Maximum sizes of each dimension of a grid: 65535 x 65535 x 1
...
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 5.5, CUDA Runtime Version = 5.5, NumDevs = 1, Device0 = GeForce 320M

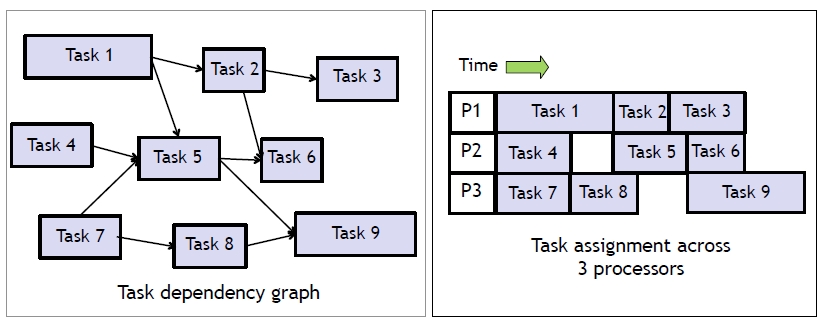
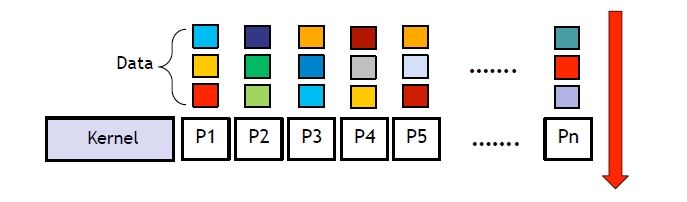


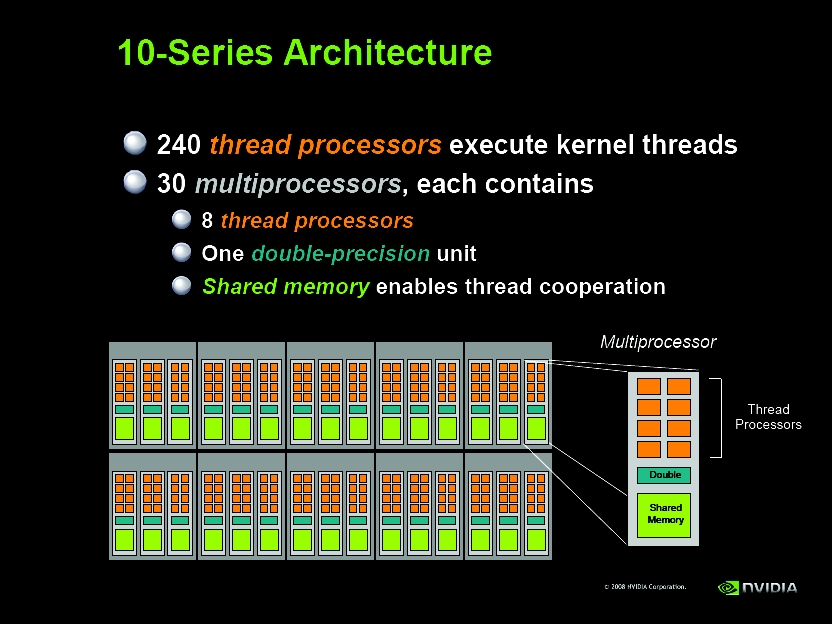

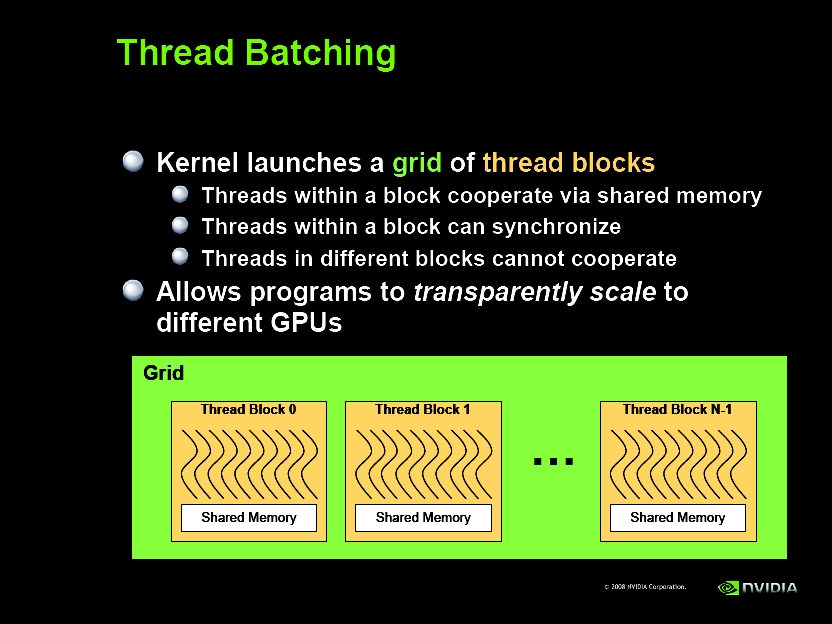




{kind=link}